Publicado por Ralph Kimball en 2015
Archivado en Planificación y gestión de proyectos
El datawarehousing nunca ha sido tan valioso e interesante como es ahora. Tomar decisiones basadas en los datos es tan fundamental y obvio que la generación actual de usuarios de negocio y diseñadores/implementadores de data warehouses no podrían imaginar un mundo sin acceso a los datos. Me resistiré al impulso de contar historias sobre como era antes de 1980.
Pero este es un momento de cambio en la práctica del datawarehousing. Es esencial que el "data warehousing" siempre recopile las necesidades del negocio y enumere todos los activos de datos de una organización en el sentido más amplio posible. Si el DWH se relega simplemente a informar sobre datos de textos y métricas obtenidos a partir de los registros transaccionales, entonces grandes oportunidades se perderán.
El data warehousing ha definido una arquitectura para la publicación de los datos correctos útil para aquellos que toman las decisiones, y esa arquitectura recibe nombres: modelado dimensional, tablas de hechos, tablas dimensionales, claves subrogadas, dimensiones de variación lenta, dimensiones conformadas y muchas más.
Actualmente, están teniendo lugar grandes cambios en mundo empresarial, con nuevos torrentes de datos procedentes de las redes sociales, texto libre, sensores y medidores, dispositivos de geoposicionamiento, satélites, cámaras y otros dispositivos de grabación. Los usuarios de negocio esperan tomar decisiones basadas en estas otras fuentes de datos.
Marketing, el líder tradicional del DWH, compite ahora con los procesos de producción y la investigación. Muchos de estos departamentos nuevos en el análisis de datos construyen sus propios sistemas, normalmente de buena fe, pero ignorando el profundo legado y las habilidades arquitectónicas acumuladas del data warehousing. Es obligatorio para la comunidad DWH conocer a estos nuevos usuarios de negocio, no sólo para ofrecer nuestras útiles perspectivas, sino también para aprender nosotros sobre estas nuevas áreas de negocio.
En este, mi último consejo de diseño en el Grupo Kimball, describiré como creo que están cambiando los componentes más importantes del data warehousing y como cambiarán en el futuro cercano. ¡Es un momento emocionante y desafiante para ser un profesional del data warehouse!
Si el DWH va a abarcar todos los activos de datos de una organización, entonces tendrá que tratar con enormes torrentes de datos nuevos provenientes de datos estructurados de manera heterogénea. Diversos cambios importantes tendrán lugar en el entorno ETL:
Los proveedores de RDBMS tienen el reto de diferenciar las capas de almacenamiento, de matadatos, y de consultas. Esto ya sucede en el entorno abierto Hadoop bajo el sistema de distribución de archivos (HDFS). Esto significa que el procesamiento ETL en algunas ocasiones puede ser retrasado hasta cierto punto en el tiempo después de que los datos hayan sido cargados en archivos accesibles. Las herramientas de consulta y análisis, a través de los metadatos, deberán ser capaces de seleccionar el esquema objetivo en el momento de consulta (como una forma potente de virtualización en el momento de la consulta, no en el momento de la carga). Tan inusual como suena un "schema on read", no es más que otra forma de virtualización de datos como las que hemos estado utilizando desde más de una década.
La desventaja de todas estas formas de virtualización se encuentra en sustituir el cálculo en la fase de ETL, lo que tiene una penalización significativa en el rendimiento. En algún punto posterior a la fase exploratoria, el diseñador normalmente volverá atrás y realizará un proceso normal ETL para preparar estructuras de archivos con más prestaciones.
Las bases de datos relacionales son y serán los fundamentos del data warehousing. Pero el RDBMS nunca se extenderá de una forma nativa a procesar todos los nuevos tipos de datos. Muchas de las herramientas analíticas especializadas compiten ente ellas para analizar los datos, y gratamente coexisten con bases de datos RDBMS. Las bases de datos relacionales seleccionaran aquellos partes de los flujos de datos entrantes que puedan soportar.
Otra cuestión relacionada: Archivar nunca será lo mismo. El almacenamiento en disco ha ganado la batalla como opción para el almacenamiento a largo plazo por diversas razones, pero el factor más significativo es el increíble bajo coste por petabyte. Además el almacenamiento en disco siempre está en línea, así los datos archivados permanecen activos y accesibles, esperando a nuevos modos de análisis, y nuevas preguntas retrospectivas. A esto se llama archivado activo.
Incluso en el desafiante nuevo mundo de extraños tipos de datos y procesamiento no relacional, el modelado dimensional es enormemente relevante. Incluso los tipos de datos más extraños pueden ser tomados como un conjunto de observaciones recopilados en el mundo real. Estas observaciones siempre tienen contexto: fecha, hora, localización, cliente/persona/paciente, acción, etc. Estas, por supuesto, son nuestras dimensiones familiares. Cuando nos damos cuenta de ello, de repente toda la maquinaria dimensional que nos es familiar nos golpea. Podemos incluir cuidadas dimensiones de alta calidad desde nuestra fuente de datos EDW. Abrid vuestras mentes: Esta inclusión no tiene que realizarse mediante la unión de una base de datos relacional convencional, porque la correspondencia se puede hacer de otras formas.
Las dimensiones, por supuesto, son el alma del data warehousing. Los hechos son meras observaciones que siempre existen en un contexto dimensional. Para ir más lejos, podemos esperar que las dimensiones lleguen a ser más importantes para poder apoyar un comportamiento más sofisticado de las consultas de base y los análisis predictivos. Ya ha habido propuestas para generalizar el esquema de la estrella, a un esquema supernova. En el esquema de una supernova, los atributos dimensionales llegan a ser objetos complejos y no un simple texto. Las dimensiones Supernova también pasan a ser más maleables y extensibles de una análisis a otro. Compara el análisis de la dimensión del cliente tradicional con la dimensión cliente supernova en la Figura 1. Date cuenta de que la mayoría de esto no son castillos en el aire. Hoy puedes generalizar una simple dimensión de un atributo en un ARRAY de STRUCTS. Hora de leer el manual de referencia SQL.
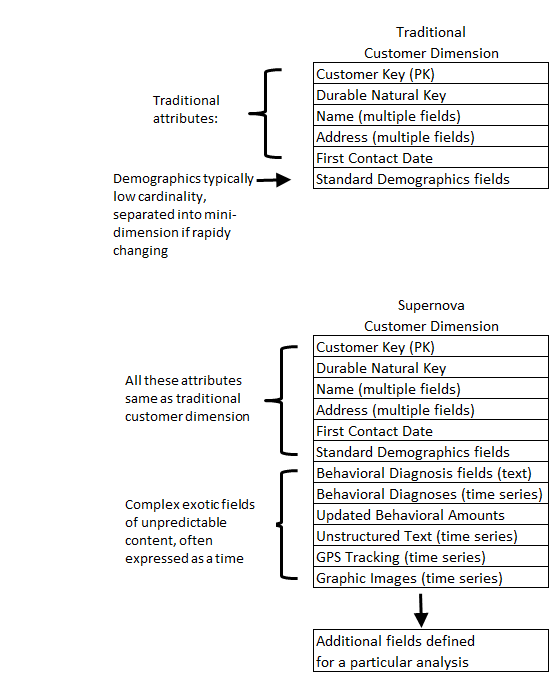
Figura 1: Dimensiones de cliente tradicional y supernova.
El lugar de las herramientas BI aumentará para incluir más tipos de análisis no SQL. Por supuesto ya ha sucedido, especialmente en el entorno abierto Hadoop, y nosotros siempre nos hemos basado en herramientas potentes no SQL como SAS. De algún modo, tocará definir de nuevo que es una herramienta BI. Comento este punto principalmente para empujar a los equipos de data warehousing a expandir su alcance y que no queden excluídos de las nuevas fuentes de datos y nuevos tipos de análisis.
He resaltado muchas veces que un profesional con éxito del data warehouse debe interesarse en tres cosas: el negocio, la tecnología y los usuarios de negocio. Esto siempre será verdad en el futuro. Si quieres pasar el tiempo codificando y sin dirigirte a los usuarios de negocio, es genial pero no perteneces al equipo de data warehouse.
Una vez dicho esto, los profesionales del DWH que quieran ir más allá necesitan tener habilidades en Unix y Java como mínimo, y estar familiarizado con algunos de los principales entornos analíticos no SQL como Spark, MongoDB y HBase, así como herramientas de transferencia de datos como Sqoop.
Creo que el reto más emocionante es la expansión de la descripción del trabajo del profesional del DWH. De repente aparecen nuevos departamentos que intentan luchar con torrentes de datos y que probablemente están reinventando la rueda del data warehouse. Encuentra cuáles son estos departamentos y edúcalos en la importancia de las dimensiones conformadas y las claves subrogadas. Ofréceles adjuntar tu dimensiones EDW de alta calidad a sus datos.
Y como dice Margy: sal adelante y sé dimensional

Artículo original: Kimball Group

Ralph Kimball es el fundador de Kimball Group y de Kimball University donde ha impartido clases sobre diseño de data warehouses a más de 10.000 estudiantes. Es el autor del best seller Data warehouse Toolkit. Ha dedicado 4 décadas diseñando sistemas DWH simples y rápidos.

